
Daniel Anderson
Assistant Teaching Professor at Carnegie Mellon University
Contact:Room 4124, Gates Hillman Center
Carnegie Mellon University
4902 Forbes Avenue
Pittsburgh, PA 15213, USA
Email: dlanders at cs dot cmu dot edu
Research Interests
I love algorithms. My research has revolved around both the theory of algorithms, i.e., designing provably efficient algorithms for interesting problems, and the practical application of algorithms to real-world problems. To me, the most exciting results are those that involve both -- seeing significant theoretical work pay off in the form of a solution to a real-world problem. I have applied my work in many different application domains, including fluid simulation, discrete optimization, and fabrication. My current work predominantly focuses on parallel computing, and in particular, algorithms and systems for handing large dynamic datasets. A full chronological list of publications can be found here.
Concurrent Memory Management
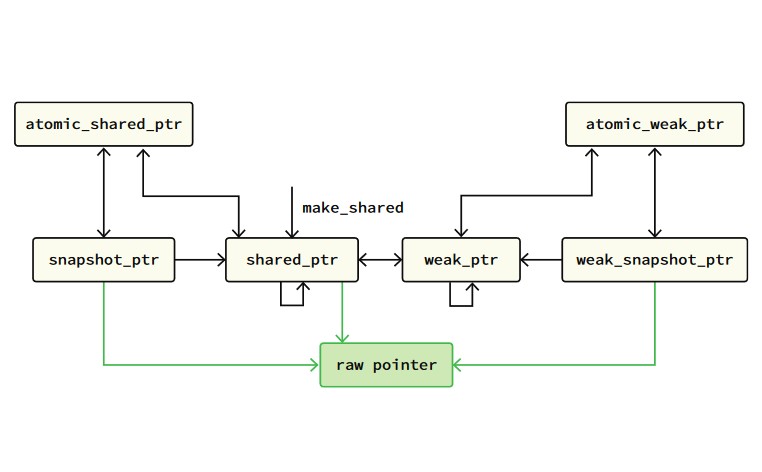
Memory reclamation, the problem of freeing allocated memory in a safe manner, is essential in any program that uses dynamic memory allocation. A block of memory is safe to reclaim only when it can not be subsequently accessed by any thread of the program. Determining exactly when this is the case is, however, a difficult problem, and even more so for mutlithreaded programs which could be sharing, copying, or modifying references to the same memory blocks concurrently. Traditional solutions for safe memory management are filled with tradeoffs. One choice is to use a language with automatic garbage collection, but this can inhibit performance and make it more difficult for programmers to implement certain data structures.
Techniques such as Hazard Pointers can be used, but often require non-trivial and error-prone modifications to the data structures, and are not applicable to all data structures. Reference-counted pointers are a popular solution among programming languages standard libraries, appearing as the main method of automatic reclamation in C++ and Rust, for example. Opponents of reference counting will tell you, however, that reference counting is simply too slow for high-performance applications.
In our work, we designed a technique for automatic memory reclamation that combines the simplicity of using reference-counted pointers with the performance of tricky manual techniques such as Hazard Pointers. We show that a completely automatic technique can compete with the state-of-the-art manual techniques in most cases within a factor of two in performance, while using substantially less memory in cases where they are outperformed. Our follow-up work shows that completely automatic techniques can compete with any manual technique such as Read-Copy-Update (RCU), acheiving throughput that matches the state-of-the-art manual schemes but with the usability of automatic RAII-based ownership.
Relevant Work
-
A Fast Wait-Free Solution to Read-Reclaim Races in Reference Counting
Ivo Gabe de Wolff, Daniel Anderson, Gabriele K. Keller, Aleksei Seletskiy
30th International European Conference on Parallel and Distributed Computing (EuroPar 24), 2024
[Code] -
Making Concurrent Reference Counting as Fast as Manual Safe Memory Reclamation
Daniel Anderson, Guy E. Blelloch, Yuanhao Wei
The 43rd ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI 2022), 2022
[Conference Paper] [DOI] [Code] -
Concurrent Deferred Reference Counting with Constant-Time Overhead
Daniel Anderson, Guy E. Blelloch, Yuanhao Wei
The 42nd ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI 2021), 2021
[Conference Paper] [DOI] [Code]
Libraries and Tools for Parallel Programming
Writing correct and efficient parallel code is challenging, even for parallel programming experts. Parallel programming is permeated with pitfalls, such as task granularity, which can make theoretically efficient code run extremely slow if not handled correctly, and race conditions, which can cause subtle and hard to reproduce bugs.
To help make writing correct and efficient code easier, our research group has put together ParlayLib, a C++ library of useful, efficient, and easy-to-use parallel primitives. ParlayLib was released as open-source software at SPAA 2020.
Relevant Work
-
Big Atomics
Daniel Anderson, Guy E. Blelloch, Siddhartha V. Jayanti
[Preprint] -
Parallel Block-Delayed Sequences
Sam Westrick, Mike Rainey, Daniel Anderson, Guy E. Blelloch
The 27th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP 22), 2022
[Conference Paper] [DOI] -
Poster: The Problem-Based Benchmark Suite (PBBS) Version 2
Guy E. Blelloch, Yihan Sun, Magdalen Dobson, Laxman Dhulipala, Daniel Anderson
The 27th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP 22), 2022
[Poster Paper] [DOI] [Library] -
Brief Announcement: ParlayLib — A toolkit for parallel algorithms on shared-memory multicore machines
Guy E. Blelloch, Daniel Anderson, Laxman Dhulipala
The 32nd ACM Symposium on Parallelism in Algorithms and Architectures (SPAA 20), 2020
[Brief Announcement] [DOI] [Library]
Parallel Graph Algorithms
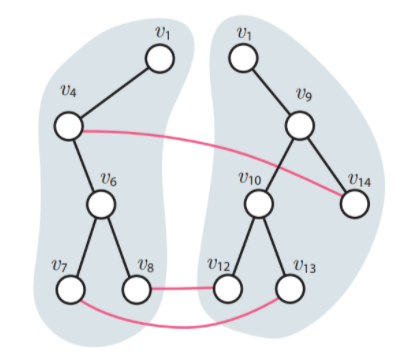
Many of today's large datasets are graphs, collections of vertices connected by edges. The Microsoft Academic Graph, for example, consists of 179 million vertices and 2 billion edges. The hyperlink web graph, the largest known publically available graph has over 3.5 billion vertices and 128 billion edges, and the Facebook graph, the largest known graph dataset, has over one billion vertices and one trillion edges. To make processing graphs of this size feasible, researchers and practitioners are turning to parallel and distributed algorithms.
We have worked on parallel algorithms for the minimum cut problem, which is to find a partition of the vertices of the graph into two groups such that the total weight of all edges that cross between the two groups is as small as possible. Prior to our work, all known parallel algorithms for the minimum cut problem were less theoretically-efficient than their sequential counterparts. That is, although they were parallel, they performed more work in total. In our research, we have designed the first work-efficient parallel algorithm for minimum cuts. An algorithm is called work efficient if it performs asymptotically no more work than the best sequential algorithms for the same problem.
Relevant Work
-
Parallel Minimum Cuts in \(O(m \log^2(n))\) Work and Low Depth
Daniel Anderson, Guy E. Blelloch
The 33rd ACM Symposium on Parallelism in Algorithms and Architectures (SPAA 21), 2021
 SPAA 2021 Best Paper award
SPAA 2021 Best Paper award
[Conference Paper] [Preprint] [DOI]
Parallel Batch-Dynamic Algorithms
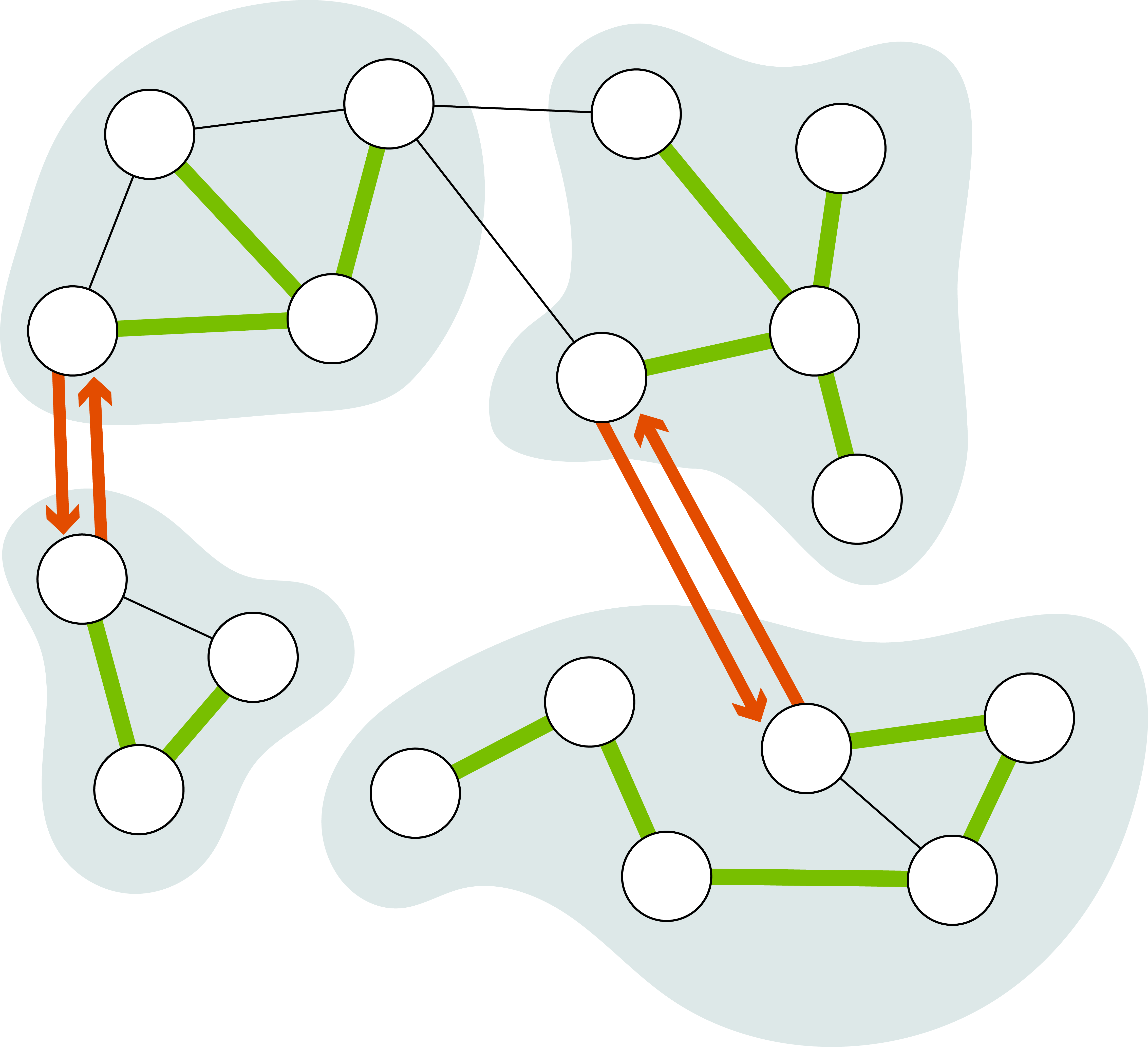
A prominent feature of many modern computer systems is the scale and the amount of data that they process. For example, Google reported in 2008 that their mapreduce clusters process over 20 petabytes of data per day, and Facebook reports processing over four petabytes of data daily. However, large data sets like this are usually not static but evolve continuously. A social network graph, for instance, may consist of billions of vertices and trillions of edges that undergo rapid but relatively small changes. Updating analyses over this data in work and time sub-linear in the size of the overall dataset is therefore important to obtain strong real-time bounds on responsiveness and the accuracy of results with respect to changes.
Such problems have traditionally been studied under the theoretical lense of dynamic algorithms, but classic dynamic algorithms are typically designed to handle only one change in the data at a time. With modern systems undergoing large batches of changes, we have taken to designing and analysing batch-dynamic algorithms, which work on batches of updates. Compared to their traditional counterparts, batch-dynamic algorithms usually perform less work, and enable significantly more parallelism within the updates. Our focus has been predominantly on graph algorithms, where we have obtained efficient parallel batch-dynamic algorithms for graph connectivity, dynamic trees, and minimum spanning trees.
Relevant Work
-
Deterministic and Low-Span Work-Efficient Parallel Batch-Dynamic Trees
Daniel Anderson, Guy E. Blelloch
The 36th ACM Symposium on Parallelism in Algorithms and Architectures (SPAA 24), 2024
[Conference Paper] [Preprint] [DOI] -
Parallel Batch-dynamic Trees via Change Propagation
Umut A. Acar, Daniel Anderson, Guy E. Blelloch, Laxman Dhulipala, Sam Westrick
The 28th Annual European Symposium on Algorithms (ESA 2020), 2020
[Conference paper] [Preprint] [DOI] -
Work-efficient Batch-incremental Minimum Spanning Trees with Applications to the Sliding Window Model
Daniel Anderson, Guy E. Blelloch, Kanat Tangwongsan
The 32nd ACM Symposium on Parallelism in Algorithms and Architectures (SPAA 20), 2020
[Conference paper] [Preprint] [DOI] -
Parallel Batch-Dynamic Graph Connectivity
Umut A. Acar, Daniel Anderson, Guy E. Blelloch, Laxman Dhulipala
The 31st ACM Symposium on Parallelism in Algorithms and Architectures (SPAA 19), 2019 [Conference paper] [Preprint] [DOI]
Parallel Self-Adjusting Computation
Since many huge datasets are not static but are frequently evolving, systems for maintaining up-to-date analyses over changing datasets are becoming highly relevant. On the theory side, researchers develop dynamic algorithms to provide theoretical guarantees on the runtime of updates. However, implementing efficient dynamic algorithms is challenging, and even more so in the parallel setting. To ease the burden on programmers, self-adjusting computation is a paradigm that allows them to implement static algorithms, which are automatically converted to dynamic ones by tracking the data dependencies of the program, allowing for updates in the input to be propagated to the output without rerunning the algorithm from scratch.
We are developing a system for parallel self-adjusting computation, which allows programmers to write static parallel algorithms that are automatically converted into dynamic ones. For example, say that a programmer wishes to maintain the minimum element in a sequence, subject to frequent updates to its elements. They could choose to implement a range query tree data structure, but such a data structure is quite non-trivial, even without involving parallelism. Instead, in our framework, the programmer can implement a simple static algorithm for computing the minimum element of an array, and have it automatically dynamized.
Relevant Work
-
Efficient Parallel Self-Adjusting Computation
Daniel Anderson, Guy E. Blelloch, Anubhav Baweja, Umut A. Acar
The 33rd ACM Symposium on Parallelism in Algorithms and Architectures (SPAA 21), 2021
[Conference Paper] [Preprint] [DOI] [Code]
Solving Mixed-Integer Programs
Many real-world optimization problems are best solved by, or are only currently solvable by encoding them as mixed-integer programs (MIPs). Modern MIP solvers are capable of solving some problems with thousands, or sometimes even millions of variables and constraints. The dominant method for MIP solving is the branch-and-cut framework, which combines the branch-and-bound method with cutting plane generation to significantly reduce what would otherwise amount to a complete enumeration of the search space.
We have worked on several problems relating to the branch-and-bound method, with applications that produce real speedups for MIP solvers on state-of-the-art benchmark problems. For example, selecting branching variables in the branch-and-bound method badly can lead to significant increases in the search tree size, so we have worked on algorithms for the selection of good branching variables. Selecting the optimal variable can be shown to be NP-Hard, but in our work, we analysed a theoretical model of branch-and-bound trees and used this to derive better heuristics. These results allowed us to implement better branching rules in SCIP, the current state-of-the-art academic MIP solver. For MIPs that require large search trees, we observed that these better branching strategies can lead to speedups of 10% or more.
We have also explored using online data from branch-and-bound trees to predict the final size of the search tree. This provides several benefits. In addition to providing an estimated runtime for the procedure, something that is commonly lacking in solvers for hard combinatorial optimization problems, it also enables several algorithmic improvements. We showed that sufficiently good tree size estimations can be used as an ingredient to produce restart strategies, i.e. heuristics that prompt the branch-and-bound algorithm to restart with a new search tree if the current one looks unfavourable. When implemented in SCIP, these strategies improve the runtime for hard MIP instances by 10%.
Relevant Work
-
Estimating the Size of Branch-and-Bound Trees
Gregor Hendel, Daniel Anderson, Pierre Le Bodic, Marc E. Pfetsch
INFORMS Journal on Computing, 2021
Published online: October 29, 2021
[Journal Paper] [Preprint] [DOI] -
Further Results on an Abstract Model for Branching and its Application to Mixed Integer Programming
Daniel Anderson, Pierre Le Bodic, Kerri Morgan
Mathematical Programming, 190, 811–841 (2021)
Published online: 27 August 2020
[Journal Paper] [Preprint] [DOI] -
Clairvoyant restarts in branch-and-bound search using online tree size estimation
Daniel Anderson, Gregor Hendel, Pierre Le Bodic, Merlin Viernickel
The 33rd AAAI Conference on Artificial Intelligence (AAAI 19), 2019
[Conference paper] [Preprint] [DOI] [Code]
Computational Fabrication

Since the advent of personal fabrication devices such as 3D printers and desktop laser cutters, designing and creating customized physical objects has become increasingly accessible to wider groups of users. When designing laser-cut objects for fabrication, an important economic concern for designers is the layout of parts of their design onto material sheets. This process is even more complicated if the material sheets that they would like to use contain pre-existing holes from cutting a previous design, as the designer must be careful to not overlap any part of their design with a hole.
We designed a tool for personal fabrication that assist users with laser-cutter design by optimizing part placement onto material sheets with holes algorithmically. Existing tools that help users with part arangement typically do so only after the user has completed their design. Our goal is to help users plan their designs as they are creating them in order to ensure that their design is feasible to fabricate, allowing them to make proactive decisions in the face of material scarcity.
Relevant Work
-
Fabricaide: Fabrication-Aware Design for 2D Cutting Machines
Ticha Sethapakdi, Daniel Anderson, Adrian Reginald Chua Sy, Stefanie Mueller
The 2021 ACM CHI Conference on Human Factors in Computing Systems (CHI 2021), 2021
[Conference Paper] [Project Page] [DOI] [Video] [Code]
Numerical Methods for Fluid Simulation
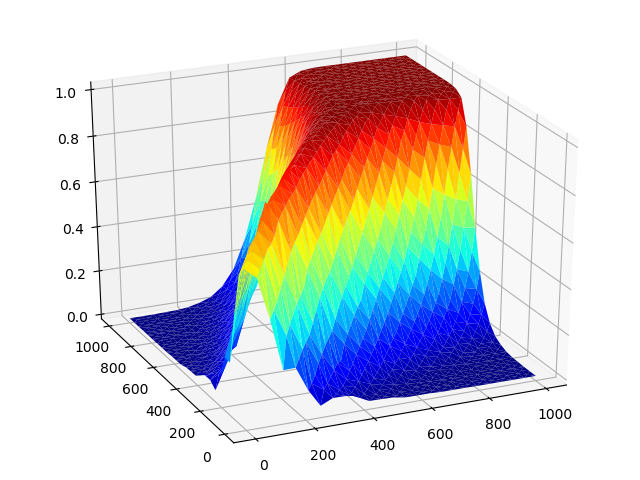
Complex processes in fluid dynamics are usually modeled using partial differential equations (PDEs), or systems of them. These systems are, however, almost always too difficult if not impossible to solve analytically, and so one must resort to using numerical approximation algorithms to obtain practically useful results. While generic methods exist to solve simple PDEs, the systems of coupled PDEs that arise in many real-world problems are often so complex that they require entire methods be designed just for them.
We worked on the design and analysis of a method for a system sometimes called the Peaceman Model, a model that describes the concentration of a solvent injected at point into a reservoir as fluid is recovered from another point. Existing schemes for this model were often of low-order accuracy or, even worse, constrained to very simple mesh geometries, which are particularly unsuited to real-world applications. The method that we developed was based on anadaptation of the hybrid high-order method, an arbitrary-order scheme for diffusion equations on generic meshes. We showed both that the method is theoretically stable, and that it produces high-quality results on read-world problem data.
Relevant Work
-
An Arbitrary-order Scheme on Generic Meshes for Miscible Displacements in Porous Media
Daniel Anderson, Jérôme Droniou
SIAM Journal on Scientific Computing, 40 (4), B1020-B1054, 2018
[Journal paper] [Preprint] [DOI] [Code]
Advisors and Collaborators
I am fortunate to have worked with the following people throughout my studies and research career:
Jérôme Droniou, Pierre Le Bodic, Kerri Morgan, Graeme Gange, Gregor Hendel, Merlin Viernickel, Umut Acar, Guy Blelloch, Laxman Dhulipala, Sam Westrick, Kanat Tangwongsan, Marc Pfetsch, Ticha Sethapakdi, Hao Wei, Stefanie Mueller, Mike Rainey