
Daniel Anderson
Assistant Teaching Professor at Carnegie Mellon University
Contact:Room 4124, Gates Hillman Center
Carnegie Mellon University
4902 Forbes Avenue
Pittsburgh, PA 15213, USA
Email: dlanders at cs dot cmu dot edu
I am a teaching faculty member in the Computer Science Department at Carnegie Mellon University. I love teaching, researching, and writing about algorithms. My research interests are broadly in the area of of parallel computing, specifically, designing parallel algorithms and implementing libraries that make parallel programming easier for programmers. These days, I spend most of my time on teaching! I am currently teaching 15-210 Parallel and Sequential Data Structures and Algorithms with Danny Sleator.
Teaching
I love teaching programming, maths, and computer science. I've been teaching college-level computer science for over nine years, and before that, I tutored high school maths for several years. My first job in high school was teaching martial arts to children!
I was incredibly honored to recieve the Herbert A. Simon Award for Teaching Excellence in Computer Science in 2024. I am beyond grateful to every student who nominated or voted for me, and to every student who has taken and enjoyed one of my classes. It means the world to me. I was also the recepient of the 2022 Alan J. Perlis Graduate Student Teaching Award as a PhD student in SCS.
At Carnegie Mellon University
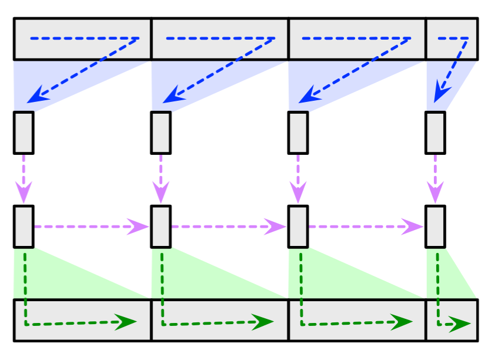
Period: Spring, 2026
Role: Instructor
Instructor: Prof. Danny Sleator & Me
Period: Fall, 2025
Role: Instructor
Instructor: Prof. Danny Sleator & Me
Period: Summer, 2025
Role: Instructor
Instructor: Me
Period: Spring, 2025
Role: Instructor
Instructor: Prof. David Woodruff & Me
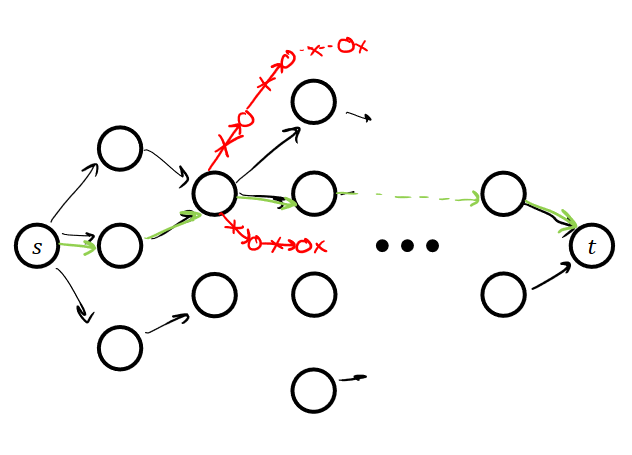
Period: Fall, 2024
Role: Instructor
Instructor: Prof. Jason Li & Me

Period: Spring, 2024
Role: Instructor
Instructor: Prof. David Woodruff & Me
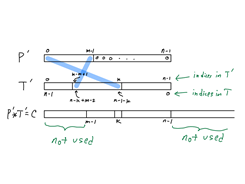
Period: Fall, 2023
Role: Instructor
Instructor: Prof. Danny Sleator & Me

Period: Fall, 2022
Role: Instructor
Instructor: Prof. David Woodruff & Me
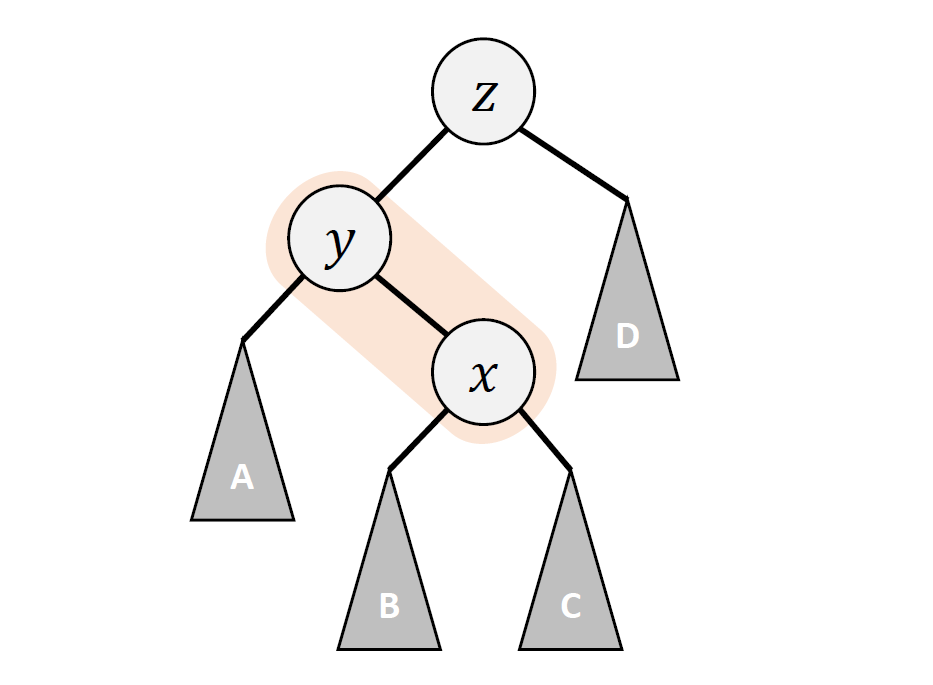
Period: Spring, 2022
Role: Teaching Assistant
Instructor: Prof. Danny Sleator &
Prof. Elaine Shi
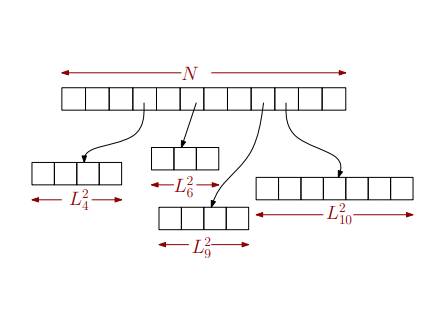
Period: Fall, 2021
Role: Teaching Assistant
Instructor: Prof. Danny Sleator &
Prof. David Woodruff

Period: Fall, 2020
Role: Teaching Assistant
Instructor: Prof. Danny Sleator
Period: Spring, 2020
Role: Teaching Assistant
Instructor: Prof. Danny Sleator
Period: Fall, 2019
Role: Teaching Assistant
Instructor: Prof. Danny Sleator
At Monash University

Period: Summer & winter, 2017 - 2018
Role: Course design & Instructor
Instructor: Me
Period: Semester One, 2018
Role: Teaching Associate
Instructor: Dr Aamir Cheema
Period: Semester Two, 2017
Role: Teaching Associate
Instructor: Prof. Graham Farr
Period: Semester One, 2017
Role: Head Teaching Associate
Instructor: Dr Arun Konagurthu
Period: Semester Two, 2016
Role: Teaching Associate
Instructor: Prof. Graham Farr
Period: Semester One, 2016
Role: Teaching Associate
Instructor: Dr Arun Konagurthu
I also enjoy coaching students for the International Collegiate Programming Contest (ICPC). I was formerly the coach of the Monash University Programming Team, and formerly a judge and problem setter for the South Pacific Programming Contests.
Recent Presentations
Lazy and Fast: Ranges Meet Parallelism in C++ (CppCon 2025)
Recent advances in the C++ standard have introduced powerful features like ranges and parallel algorithms—both aimed at writing faster, cleaner, and more expressive code. Ranges offer lazy, on-demand computation that improves I/O efficiency and composability. Parallel algorithms, on the other hand, harness multitasking to speed up compute-heavy workloads.
At first glance, these two features seem like a perfect match: lazy evaluation to minimize I/O overhead, and parallelism to maximize throughput. However, in practice, they don’t play well together. Many range operations—especially those over non-random-access sources—are inherently sequential due to their lazy pull-based, one-element-at-a-time nature.
In this talk, we’ll explore a modern library technique that unlocks the synergy between lazy ranges and parallelism. You’ll see how to build lazy, composable range pipelines that are parallel-friendly—capable of efficiently expressing operations like filter, scan, and flatten without sacrificing performance or elegance. We’ll walk through real-world examples where these techniques deliver strong parallel speedups with minimal programming overhead.
Introduction to Wait-free Algorithms in C++ Programming (CppCon 2024)
If you've attended any talks about concurrency, you've no doubt heard the term "lock-free programming" or "lock-free algorithms". Usually these talks will give you a slide that explains vaguely what this means, but you accept that is is approximately (but not quite exactly) equal to "just don't use locks". More formally, lock-freedom is about guaranteeing how much progress your algorithm will make in a given time. Specifically, a lock-free algorithm will always make some progress on at least one operation/thread. It does not guarantee however that all threads make progress. In a lock-free algorithm, a particular operation can still be blocked for an arbitrary long time because of the actions of other contending threads. What can we do in situations where this is unacceptable, such as when we want to guarantee low latency for every operation on our data structure rather than just low average latency?
In these situations, there is a stronger progress guarantee that we can aim for called wait-freedom. An algorithm is wait free if every operation is guaranteed to make progress in a bounded amount of time, i.e., no thread can ever be blocked for an arbitrarily long time. This helps to guarantee low tail latency for all operations, rather than low average latency in which some operations are left behind. In this talk, we will give an introduction to designing and implementing wait-free algorithms.
Lock-free Atomic Shared Pointers Without a Split Reference Count (CppCon 2023)
In this talk, we describe a strategy for implementing lock-free atomic shared pointers without a split reference count. The solution is surprisingly simple and elegant, as it does not require adding any fields to the shared pointer or atomic shared pointer and does not hide anything inside the bits of the pointer. Under the hood, it makes use of hazard pointers and deferred reclamation. Since hazard pointers are on track for inclusion in C++26, this implementation is timely, simple to implement with nearly-standard C++, and achieves excellent performance.
Smarter Atomic Smart Pointers (CppCon 2022)
Memory management is hard, especially for concurrent code, even for concurrency experts. To make it more manageable, C++ programmers almost always rely on high-level abstractions such as smart pointers and deferred reclamation techniques such as hazard-pointers and RCU that offer to reduce the burden. These abstractions, however, come with many tradeoffs. In this talk, we will discuss recent library solutions that aim to combine the advantages of these techniques to produce a solution that is as easy to use as smart pointers but as fast and scalable as deferred reclamation techniques. We aim to convince the audience that scalable concurrent code with the performance of expert-written code can be written using abstractions as simple as smart pointers.
Research
I was fortunate to be advised by Professor Guy Blelloch during my PhD at CMU. Prior to coming to CMU, I completed a Bachelor of Science (Honours) in Applied Mathematics at Monash University in Australia, under the supervision of Professor Jérôme Droniou. I subsequently worked as a research assistant in the Data61 lab at Monash University with Dr Pierre Le Bodic before beginning my PhD.
My main projects right now are ParlayLib, our research group's library for supporting efficient and easy-to-use fork-join parallelism in C++, and concurrent deferred reference counting, which I like to call smarter atomic smart pointers, a project where we are trying to bring efficient automatic concurrent memory management to C++. You can find more information about the kinds of research I've done on my Research page.

A C++ library for parallel programming that provides easy-to-use abstractions for fork-join parallelism and high-level parallel algorithms.
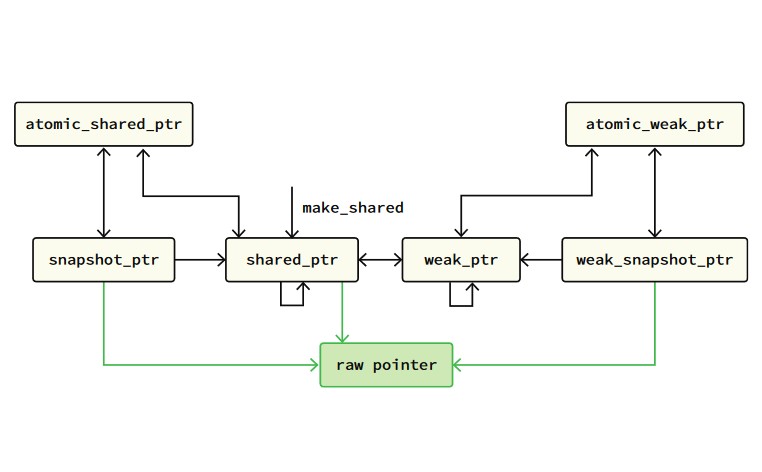
Automatic deferred reclamation (the equivalent of garbage collection in C++) with the performance of expert-written unsafe memory management.
Research supervision and advising If you are interested in supervision of an undergraduate or masters research projects or co-supervision of a PhD project (I can not be the primary supervisor), please reach out. No past experience required (I did not know a single thing about parallel algorithms before I started working with Guy!). I have limited capacity (and no funding) to take on research students, but I'm always happy to chat and see if we can find something that works. I suggest you watch the video presentations above to see whether you are interested in the kind of work that I am.